docker 运行filebeat收集日志 |
您所在的位置:网站首页 › filebeat processors › docker 运行filebeat收集日志 |
docker 运行filebeat收集日志
|
1.简介
beats
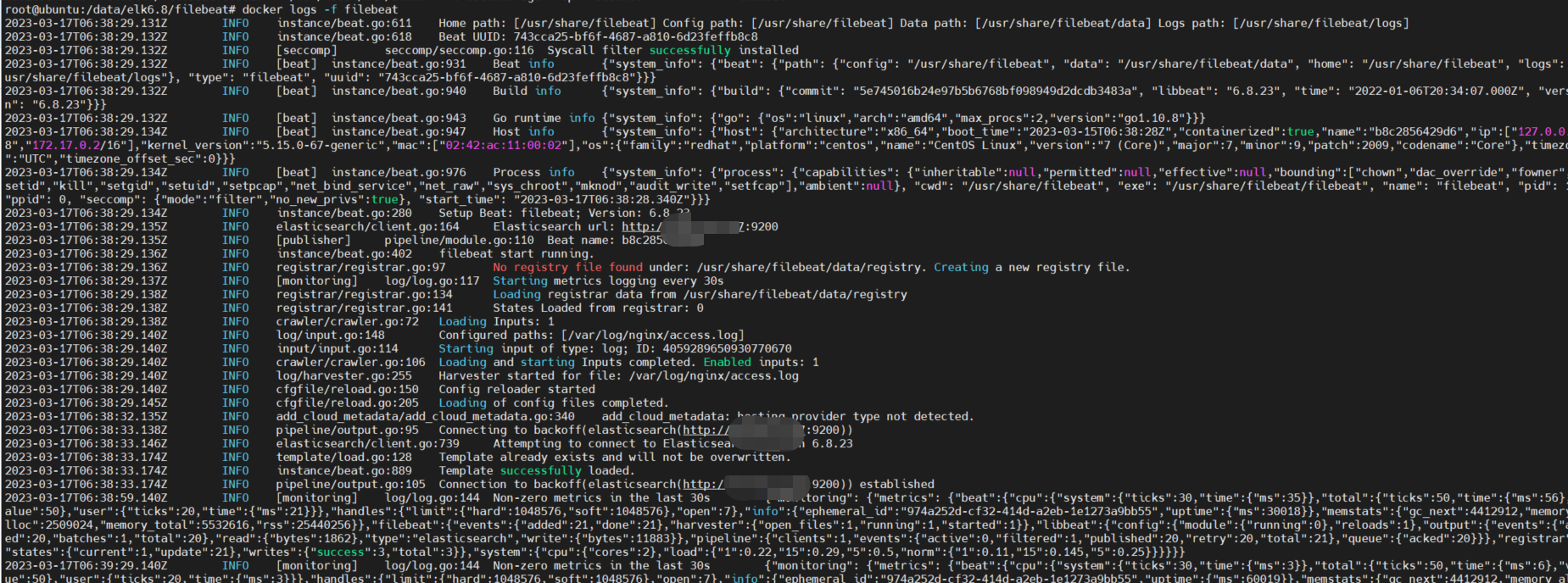
首先filebeat是Beats中的一员。 Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。 目前Beats包含六种工具: Packetbeat:网络数据(收集网络流量数据) Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据) Filebeat:日志文件(收集文件数据) Winlogbeat:windows事件日志(收集Windows事件日志数据) Auditbeat:审计数据(收集审计日志) Heartbeat:运行时间监控(收集系统运行时的数据) filebeatFilebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。 Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。 2.docker运行环境说明: docker 20.10 ubuntu 20.04 elasticsearch 6.8.23 filebeat 6.8.23(docker)测试的数据流:通过运行filebeat容器,挂载收集的日志文件,filebeat收集后发送到elasticsearch。 话不多说,接下来看看具体操作。 下载镜像,由于我的elasticsearch的版本是6.8.23,为统一版本,镜像也是下载6.8.23。 docker pull elastic/filebeat:6.8.23 运行容器拷贝出filebeat.yml配置文件: docker run -d --name filebeat elastic/filebeat:6.8.23 /bin/bash # 提前创建相关目录 mkdir -p /data/elk6.8/filebeat cd /data/elk6.8/filebeat docker cp filebeat:/usr/share/filebeat/filebeat.yml ./ # 此坑会踩 chmod go-w filebeat.yml本次测试以nginx的访问日志为例,所以如果你也一样测试的话,请先运行nginx,且配置好,我用的json格式的log。 以下是我的nginx的配置: http { ... ## # Logging Settings ## # 原有日志格式,不能注释或者去掉 log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for" $request_time'; # json日志格式 log_format log_json '{"@timestamp": "$time_local", ' '"remote_addr": "$remote_addr", ' '"referer": "$http_referer", ' '"request": "$request", ' '"status": $status, ' '"bytes": $body_bytes_sent, ' '"agent": "$http_user_agent", ' '"x_forwarded": "$http_x_forwarded_for", ' '"up_addr": "$upstream_addr",' '"up_host": "$upstream_http_host",' '"up_resp_time": "$upstream_response_time",' '"request_time": "$request_time"' ' }'; access_log /var/log/nginx/access.log log_json; ... }配置好后,重新加载nginx:nginx -s reload 然后是filebeat.yml的配置: filebeat.config: modules: path: ${path.config}/modules.d/*.yml reload.enabled: false processors: - add_cloud_metadata: ~ # 收集系统日志 filebeat.inputs: - type: log enabled: true json.keys_under_root: true # 解析json数据 json.overwrite_keys: true fields: # 绑定tag,后面输出到es时用到 tag: 'nginx-access' paths: - /var/log/nginx/access.log # 收集nginx的访问日志 output.elasticsearch: # 配置elasticsearch的地址,有xpack的插件需要添加相关auth信息 hosts: '172.30.3.57:9200' username: '${ELASTICSEARCH_USERNAME:}' password: '${ELASTICSEARCH_PASSWORD:}' indices: - index: "filebeat-%{+yyy-MM.dd}" - index: "nginx_access-%{+yyy-MM.dd}" # 指定tag为nginx-access的log输出到指定的index when.contains: fields: tag: 'nginx-access'删除之前运行的filebeat容器,重启新的容器: docker rm -f filebeat docker run -d --name filebeat \ --restart always \ -v /data/elk6.8/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \ -v /var/log/nginx/access.log:/var/log/nginx/access.log \ elastic/filebeat:6.8.23 /bin/bash观察filebeat容器的日志输出:docker logs -f filebeat
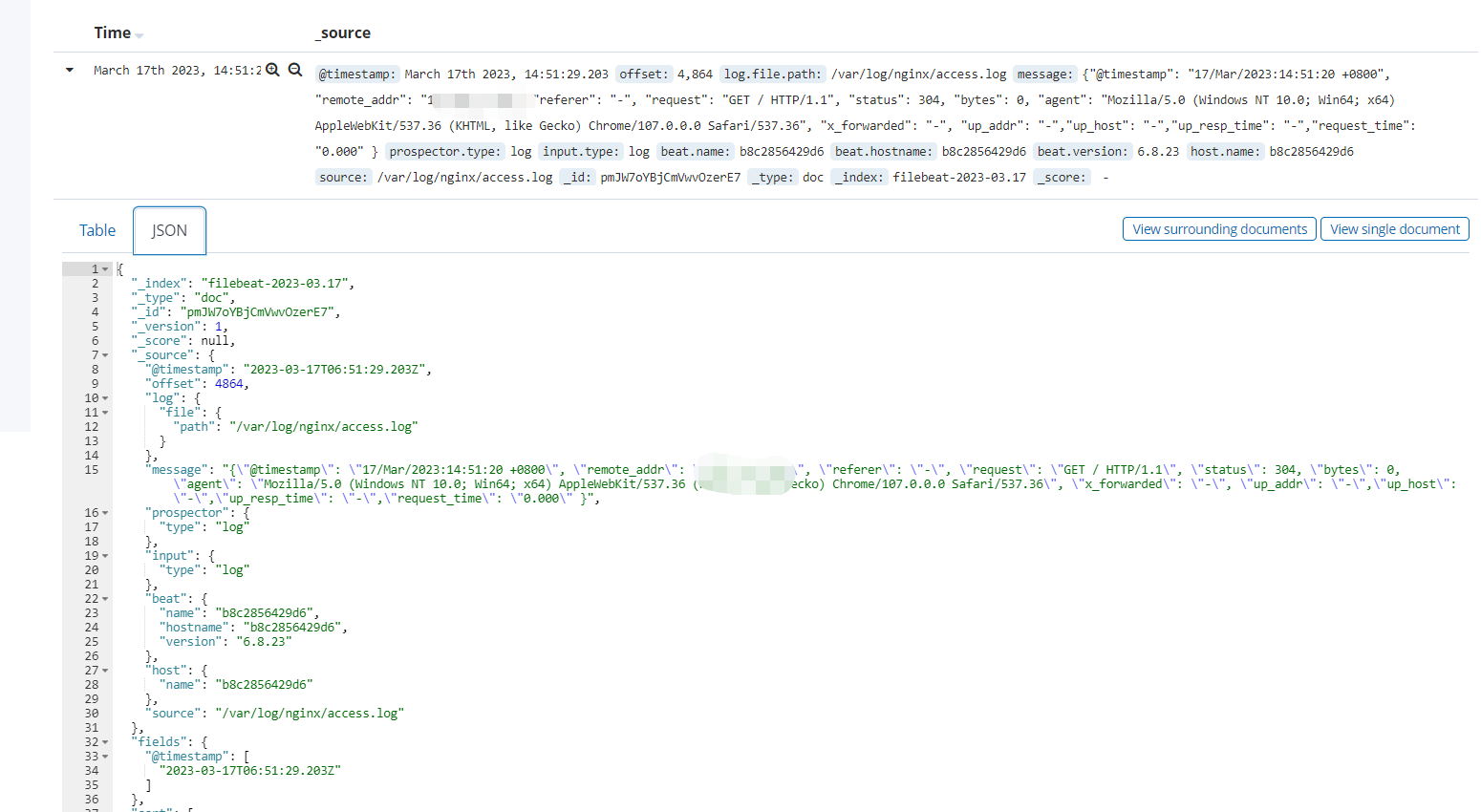
从日志来看,filebeat正常运行,接下来访问几次nginx的80端口,看看kibana的日志情况:
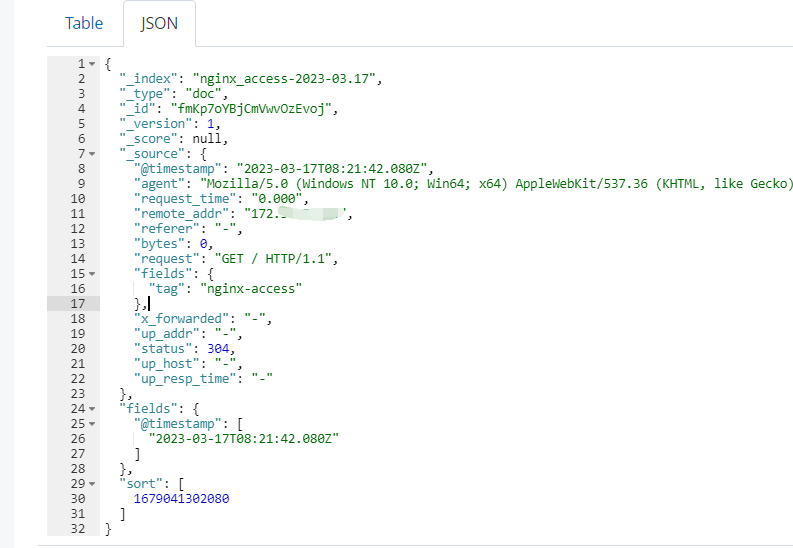
从kibana来看也是正常的,到此日志收集就结束了。 如果我们对输出到elasticsearch的字段内容有需求,毕竟filebeat在输出到es时会添加一些我们认为冗余的字段,占空间也影响看内容,我们可以添加processors处理: # processors,与output.elasticsearch同级 processors: - drop_fields: fields: ["log", "host", "input", "ecs", "beat", "error", "prospector", "source", "offset"] ignore_missing: false重启docker后面,请求几次nginx,看看输出到es的日志情况:
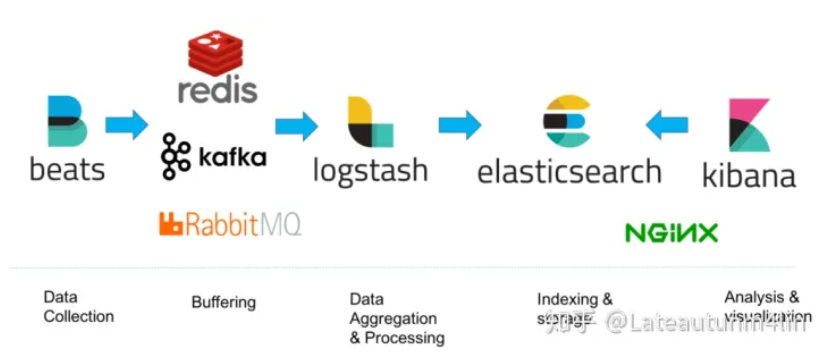
当然filebeat能做的远不止这些,filebeat也可以处理来自syslog等,输出到logstash/kafka等操作。 是不是相比之前要简洁很多,这样一套EFK下来,就基本解决简单需求,如果有更复杂的需求,比如大日志量则需要kafka缓冲,一些字段的过滤可以用到logstash的input-filter-output三步来搞定。 所以一般的数据流转我们可以采用:
参考文档: docker安装filebeat Filebeat配置使用 Filebeat的高级配置详解 filebeat自定义输出内容,去除冗余字段 nginx日志输出配置json格式 |
【本文地址】
今日新闻 |
推荐新闻 |